Understanding machine learning’s place in our lives
Each time you open Netflix on your television or tablet, the company’s software analyzes your behavior to predict the features you want to access, uses its knowledge of your favorite videos to anticipate which show you are looking for, and tests your Internet connectivity to decide the best way to provide uninterrupted service. Each of these activities is based on machine learning, a type of artificial intelligence in which a computer learns to make decisions by studying large datasets, producing mathematical models, finding patterns in the data, or predicting what should happen next. To accomplish these tasks, computers use a set of instructions called algorithms. Companies implement machine learning to provide the best experience for consumers, whether routing a shipped package or suggesting videos to stream. Machine learning is also used to improve medical decision-making and treatment, make airplane maintenance and pilot scheduling more efficient, and solve many complex scientific and engineering problems.
There are three major types of machine learning, each with its subtypes. Supervised learning starts with manually labeled data (e.g., “viewer chooses a mystery movie with teen protagonist”), for which the computer detects patterns among data points. In unsupervised learning, the computer seeks patterns in an unlabeled dataset (e.g., “viewer chose comedies on Friday night and mysteries on Sunday nights”) with little guidance. The third type of machine learning is reinforcement learning, which is based on a reward system (e.g., a computer correctly guesses the movie a viewer will choose, giving the computer a high score as a reward).

Figure 1:
Different types of machine learning (from “Towards Data Science, Reinforcement Learning”)
Supervised Learning
In supervised learning, a computer is given a dataset sorted into different categories. For example, the computer would be given a dataset of movies labeled either “user likes” or “user dislikes.” The computer then develops a mathematical model to map features (such as movie genre) to the labels of “user likes” or “user dislikes.” The computer improves the model until the error of the mapping has been minimized on test data.
One of the most common types of supervised learning creates the model using a neural network, which partially mimics how a human brain makes decisions. A neural network consists of many nodes that each process a small amount of information. When the nodes work together, they will produce a probability that a data point belongs to a certain category. One node cannot create an effective model, but the computer can use many nodes and choose the most significant ones to create the best method for decision-making, such as choosing a recommended movie. Deep learning, which is a special type of machine learning, implements very complex neural networks to analyze huge datasets.
Supervised learning has many applications across a variety of fields. Supervised learning is used by social media and online services to collect and analyze information about your preferences to identify more content you might like. Banks and credit card companies use supervised learning to detect fraud by analyzing deviations from typical purchase patterns. In real estate, supervised learning can be used to calculate the best listing price for a house using information about location, number of rooms, lot size, and other factors. Additionally, supervised learning can be used to predict how long a patient will probably stay in the hospital or to calculate the probability that a patient will develop a certain type of infection.
However, supervised learning is not always the most efficient way to develop a predictive algorithm. Having to manually label a sufficiently large training dataset can be tedious and time-consuming. If a training dataset is too small or unclear, the computer will not produce an accurate model.

Figure 2:
How supervised learning works (from: “tutorial and example”)
Unsupervised Learning
In unsupervised machine learning, the computer attempts to discern patterns in a large dataset. Usually, patterns are found through clustering, a process that identifies common characteristics of data points and assigns them to clusters. For each cluster, the computer calculates how well the datapoint fits. Each cluster has a centroid, which is the average point in that cluster, and the fit calculation determines how close a data point is to its centroid.

Figure 3:
Soft clustering of data points during the training of unsupervised machine learning, showing normal distributions centered around the centroid (μ) (from: “towards data science, Gaussian mixture models explained”)
Soft clustering permits data points to belong to more than one cluster, and hard clustering allows each data point to only belong to a single cluster. Soft clustering models can be developed based on probability constraints. In Figure 3, each cluster has a mean (μ) value, and a normal (Gaussian) distribution is centered around each mean. The computer calculates the probability that any data point is within a certain distribution. This type of modeling assumes that an independent variable influences the probability distribution; for example, the independent variable of the viewer’s age influences the choice of movie. Also, the computer does not understand the real-world significance of variables, so it may find a strong correlation between two variables that have no actual influence on one another. For example, the computer detects that a viewer often watches situational comedies and therefore suggests full-length comedy films, even though the viewer dislikes feature movies.
Despite some drawbacks, unsupervised learning has applications in many areas of study. Unsupervised learning is used by online news applications to classify stories by topic. Unsupervised learning is also being used to detect tumors in medical imaging scans and to predict missile attacks against military ships.
Unsupervised learning requires vast datasets to form models, and large amounts of reliable data are not always available. The results of unsupervised learning are often less accurate than those from supervised learning and must be verified by humans. In addition, the computer cannot explain why data were clustered in specific ways, making it difficult to understand and judge the computer’s reasoning and the results.
Reinforcement learning
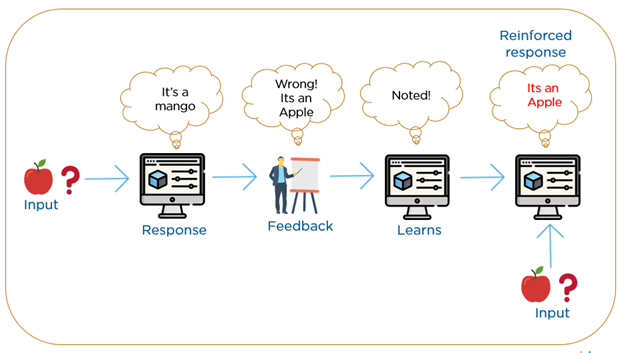
The third type of machine learning is reinforcement learning, which relies on a reward system. When the model produces a correct response, there is a ‘reward,’ which is a number indicating the correctness of the action. The computer learns to accumulate correct results and avoid errors. The reinforcement learning equation approach incorporates two numbers (between 0 and 1) set by a trainer: learning rate, which controls how fast the computer learns, and a discount factor, which determines whether the computer should try to receive short-term or long-term rewards. When the learning rate is close to 1, the computer learns quickly and highly values what has been learned most recently. When the discount factor is small, the computer focuses only on short-term rewards for obtaining the correct answer; a high discount factor favors long-term rewards.
Reinforcement learning has many practical applications. Google used reinforcement learning to create a robot that plays the complex game of Go. It can also be used to diagnose medical conditions and find the best treatment plan. Investors can use reinforcement learning to identify the best stocks to purchase and to calculate the ideal time to buy or sell, and online advertising companies use reinforcement learning to pinpoint the best ad to show as you move around the Internet.

Figure 4:
A simplified example of how reinforcement learning works
(from “towards data science, an introduction to reinforcement learning”)
Pros and Cons of Machine Learning
Although machine learning is now seamlessly integrated into many aspects of our daily lives, it still presents some issues. First, for any type of machine learning, a large dataset is required because the computer lacks the real-world experience of humans. Datasets that are too small can lead to poor training, which might cause the computer to serve a new user an advertisement or video that he or she finds offensive.
Second, retraining a machine learning model can be difficult and time-consuming. Machine learning systems that perform facial recognition may acquire the biases of their trainers, even if enormous datasets are used. Retraining these systems would require large datasets of new images that better represent all populations and labeling of all available training images in ways that do not reflect the subjective judgment of the trainers. Finally, the reasoning behind models developed through machine learning is not always apparent, making it difficult to determine how well the models are working and how to debug them.Despite these challenges, machine learning is revolutionizing many fields, including finance, healthcare, cybersecurity, image processing, self-driving vehicles, and speech recognition. In the sciences and engineering, machine learning has been widely adopted to analyze large datasets generated by bioinformatics, satellites imaging the Earth’s surface or planetary bodies, and particle physics experiments. Machine learning approaches allow computers to solve problems or find patterns in datasets that would be impossible for humans to analyze and will certainly see a much wider application in the future.
– Amelia How
Image Sources
- https://towardsdatascience.com/reinforcement-learning-101-e24b50e1d292
- https://www.tutorialandexample.com/supervised-machine-learning/
- https://towardsdatascience.com/gaussian-mixture-models-explained-6986aaf5a95
- https://towardsdatascience.com/an-introduction-to-reinforcement-learning-1e7825c60bbe



Comments are closed.